Reconocimiento de comandos por voz
Objetivos
- Familiarizarse con el procesamiento de voz en nodos AI-IoT
- Configurar un interfaz por voz offline/on-device para detección de comandos de voz
- Integrar procesamiento con voz en una solución IoT genérica
Introducción
Procesamiento de voz
Hoy en día el procesamiento digital de la voz es empleado en múltiples ámbitos, siendo tal vez uno de los más extendidos el de los asistentes de voz virtuales (Amazon Alexa, Google Assitant, Apple Siri, ...).

En su mayoría estos sistemas combinan diversas técnicas de inteligencia artificial para proporcionar un dialogo hablado con el usuario (ver esquema). La complejidad computacional y el tamaño de los modelos empleados por estos algoritmos son elevados, por lo que en su mayoría se ejecutan (online) en servidores Cloud. No obstante, debido a razones de eficiencia energética, ancho de banda, latencia y privacidad se está tendiendo actualmente a trasladar parte de este procesamiento a los propios nodos.
Wake-Up Word (WUW)
Por ejemplo, para llevar a cabo el reconocimiento de habla, los asistentes virtuales utilizan, en su mayoría, algoritmos de detección de palabras clave despertador (Wake-Up Word) para detectar el comienzo de un enunciado por parte del usuario. Estos algoritmos, de menor complejidad que otros, se ejecutan offline en el propio dispositivo (smartphone, altavoz inteligente, etc.) lo que permite una mayor eficiencia y privacidad, ya que no es necesario transferir todo el audio al Cloud.
Es preciso señalar que, puesto que se están ejecutando constantemente, la complejidad computacional y la energía requeridas por estos algoritmos debe ser las menores posibles. Esto se consigue limitando su capacidad de identificación a una sola palabra o como máximo una única frase, generalmente corta.
Reconocimiento del habla (ASR/STT)
El reconocimiento del habla, también denominado reconocimiento automático de voz, o en inglés Automatic Speech Recognition (ASR) o también Speech To Text (STT) consiste en, dado un enunciado delimitado por WUW o por otro evento (como la pulsación de un botón en el caso de push to talk), transcribirlo a texto para su posterior procesamiento (transcripción, traducción, sistemas de respuesta automática, etc.). La complejidad computacional y el tamaño de los modelos empleados suponen un obstáculo para su procesamiento offline en la mayor parte de nodos IoT, exceptuando smartphones o dispositivos de similares prestaciones, para los que existen algunas implementaciones viables.
Wordspotting
En determinados contextos, como los dispositivos controlados por comandos de voz (voice command device, VCD) no es necesario llevar a cabo un reconocimiento completo del habla y tan sólo es necesario identificar un pequeño conjunto de palabras clave (comandos), lo que se conoce con el término genérico de wordspotting o keyword spotting. Este tipo algoritmos, aunque más complejos que la detección de WUW, son mucho más sencillos que los ASR/STT y con frecuencia pueden ejecutarse offline incluso en pequeños microcontroladores.
Espectrogramas y MFCCs
Todos los algoritmos de procesamiento de voz se basan en el uso de espectrogramas que son una representación gráfica (3D) del contenido frecuencial de una señal a lo largo del tiempo.

El proceso de obtención de un espectrograma adecuado para el procesamiento de voz sería el siguiente:
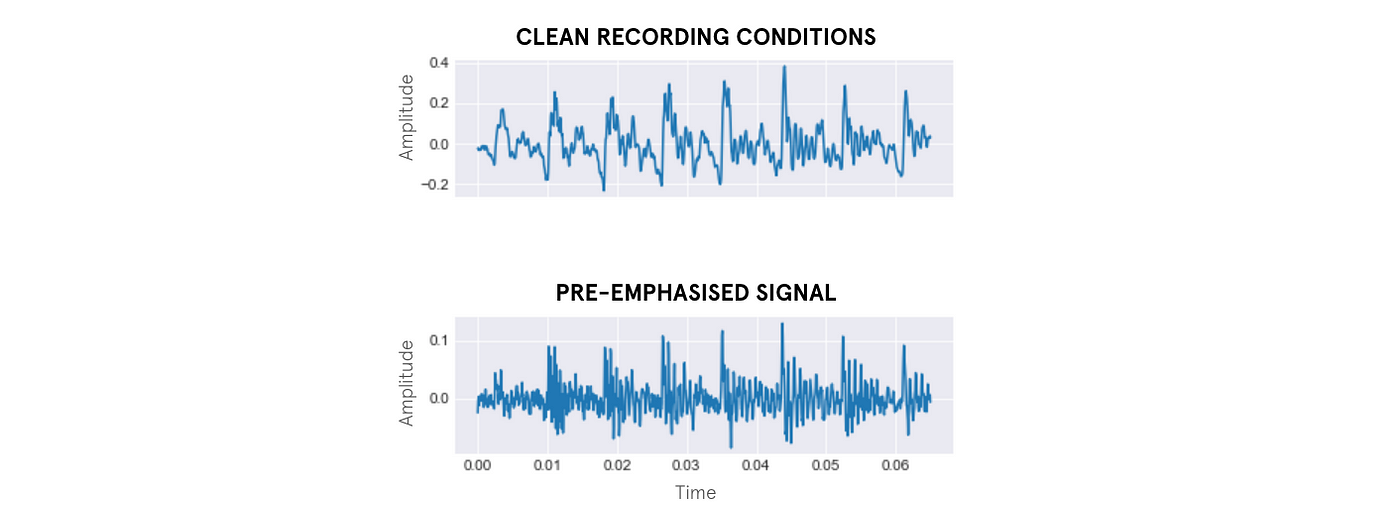
- Pre-emphasis: pre-amplificación (opcional) de las componentes de alta frecuencia de la señal de audio.
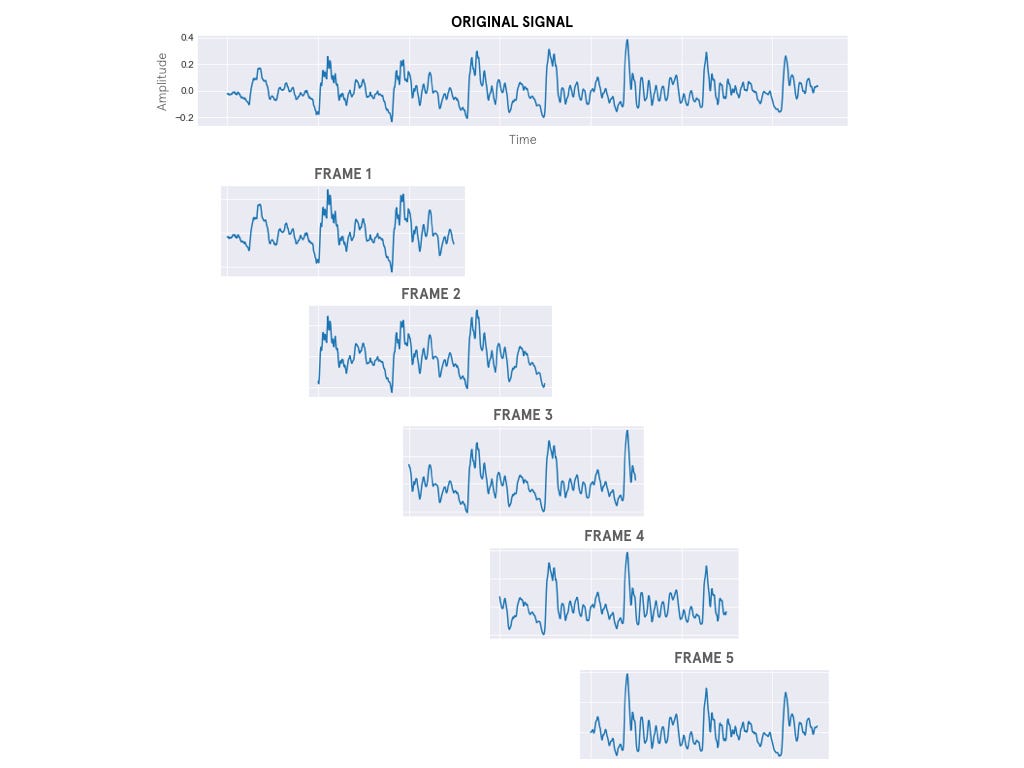
- Framing: división de la señal en un cierto número (nFrames) de ventanas temporales, habitualmente de entre 20 y 40 ms de duración.
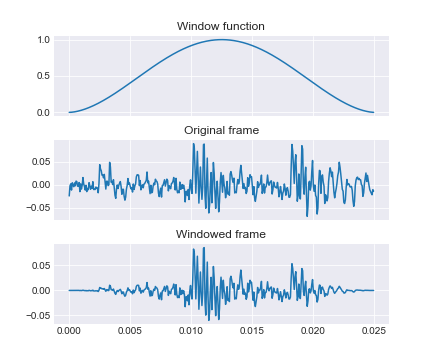
- Windowing: consiste en la aplicación de una función ventana a cada frame.
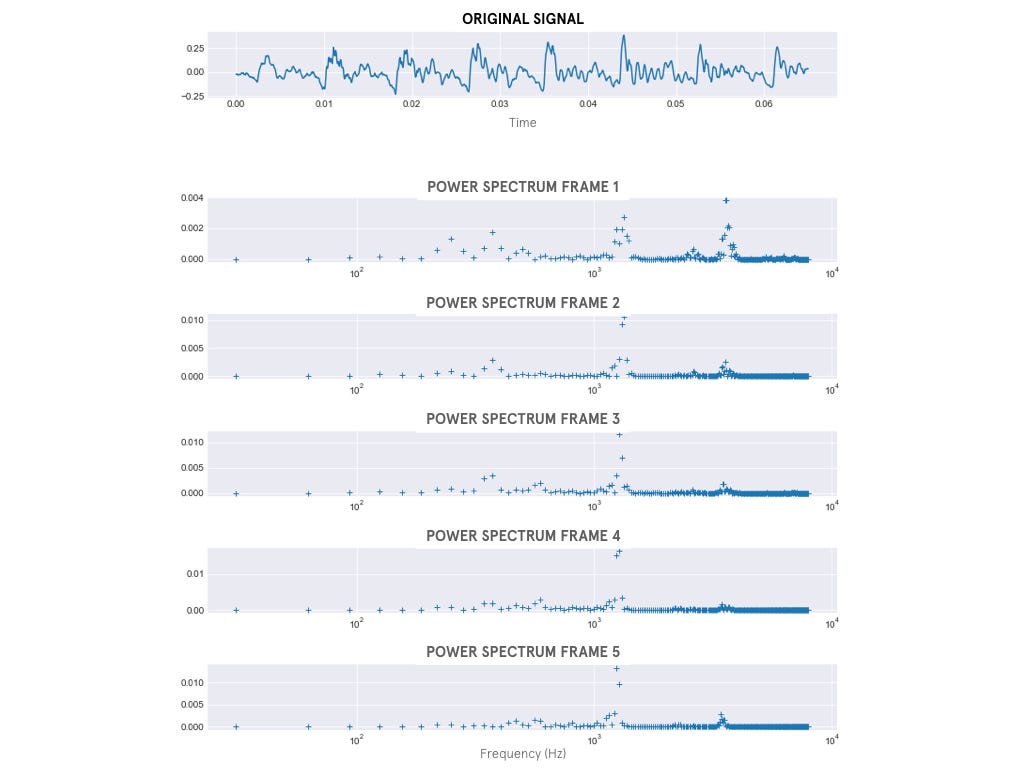
- Transformación y cálculo de la densidad espectral: consiste en el cálculo de la Transformada de Fourier de Tiempo Reducido (Short-Time Fourier-Transform o STFT) para cada frame.
- MEL scale mapping: aplicación de un banco de filtros (nFilters) correspondientes a la Escala de Mel al espectro obtenido en el paso anterior.
- Normalización: aplicación de la Transformada Discreta de Coseno (DCT) y normalización mediante la resta de la media.
El espectrograma resultante es lo que se conoce como Coeficientes Cepstrales en las Frecuencias de Mel o MFCCs (Mel Frequency Cepstral Coefficients) y es la entrada que suelen emplear los algoritmos de procesamiento de voz.
Nota
Cabe mencionar que dependiendo de algoritmo empleado es posible usar directamente el espectrograma sin aplicar el escalado de Mel.
Tarea (opcional)
Para entender este proceso seguir el ejemplo del artículo "Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What's In-Between" de Haytham M. Fayek
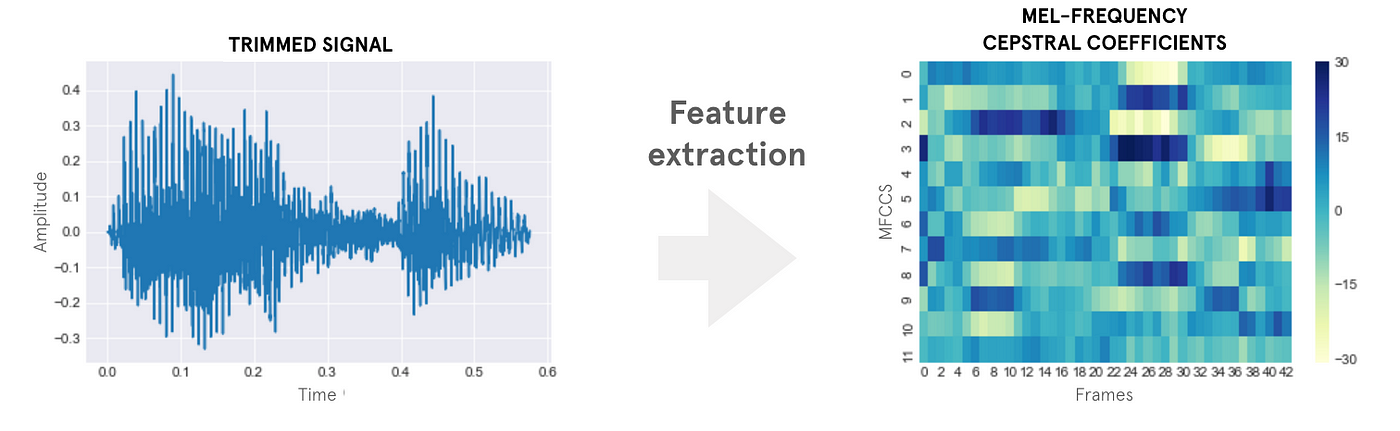
Reconocimiento de palabras clave y redes neuronales
Como hemos visto previamente los espectrogramas proporcionan una representación gráfica 3D a partir de una señal de audio, lo que ofrece la posibilidad de llevar a cabo el reconocimiento de palabras clave mediante CNNs similares a las empleadas en el reconocimiento de imágenes.
Ejemplo sencillo de CNN para el reconocimiento de palabras clave
El siguiente tutorial ilustra el proceso construcción de una CNN sencilla para el reconocimiento de 10 palabras, empleando para el entrenamiento un subconjunto de la base de datos "Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition" y empleado las utilidades propias de Tensorflow para la decodificación de los ficheros audio y la generación de los espectrogramas.
Tarea (opcional)
Seguir el tutorial.
Tarea (opcional)
Convertir el modelo entrenado a TFLite incluyendo un proceso de cuantización.
Micro Speech Example
El ejemplo “Micro Speech” de TFLM demuestra cómo implementar un sistema básico de reconocimiento de palabras clave en dispositivos con recursos limitados. Este ejemplo utiliza un modelo de red neuronal pequeño, entrenado para reconocer palabras cortas como “yes” y “no” a partir de audio en tiempo real capturado por un micrófono.
El flujo completo incluye la captura de audio, la extracción de características (específicamente espectrogramas de MFCC), la inferencia del modelo y la interpretación de los resultados, todo corriendo directamente en el microcontrolador sin necesidad de conexión a la nube. Es una referencia clave para desarrolladores que buscan añadir capacidades de reconocimiento de voz local en sistemas embebidos.
Tarea
Siguiendo la documentación del proyecto estudiar el modelo.
Version para ESP32
El componente esp-tflite-micro incluye una versión de este ejemplo adaptada para su uso en las placas de Espressif: examples\micro_speech.
Tarea
Probar el ejemplo siguiendo las instrucciones del repositorio.
Tarea entregable
Integrar el proceso de detección de palabras ("Yes/No") en tu proyecto de prácticas anteriores, de modo que, a través de voz, sea posible activar o desactivar el envío de los resultados de la inferencia sobre el modelo entrenado y desplegado en el ESP-EYE a un entorno externo (e.g. broker MQTT, Thingsboard, Telegram, etc.)
Algunas referencias
- Santosh Singh, "How speech-to-text/voice recognition is making an impact on IoT development", Featured, Internet Of Things, 2018.
- Yuan Shangguan, Jian Li, Qiao Liang, Raziel Alvarez, Ian McGraw, "Optimizing Speech Recognition For The Edge", https://arxiv.org/abs/1909.12408
- Thibault Gisselbrecht, Joseph Dureau, "Machine Learning on Voice: a gentle introduction with Snips Personal Wake Word Detector", Snips Blog, May 2 2018.
- Haytham M. Fayek, "Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What's In-Between", 2016.